Kafka as a destination (including the Confluent and Redpanda variants) is deprecated and no longer actively maintained. It remains fully functional and no code is currently being removed. For new mirrors, we recommend ClickHouse, ClickHouse Cloud, or Postgres as the destination.
Once PeerDB is connected to your PostgreSQL database or read replica, we will first do a full initial load of all the selected tables from your database. Then the continuous sync process will start using WAL to capture changes from the source database and apply them to the destination queue.Depending on the script you’ve chosen you have complete control of the format on the destination. Default is JSON.
1
Create Mirror Screen
Click on Mirrors tab and then enter new Mirror screen
2
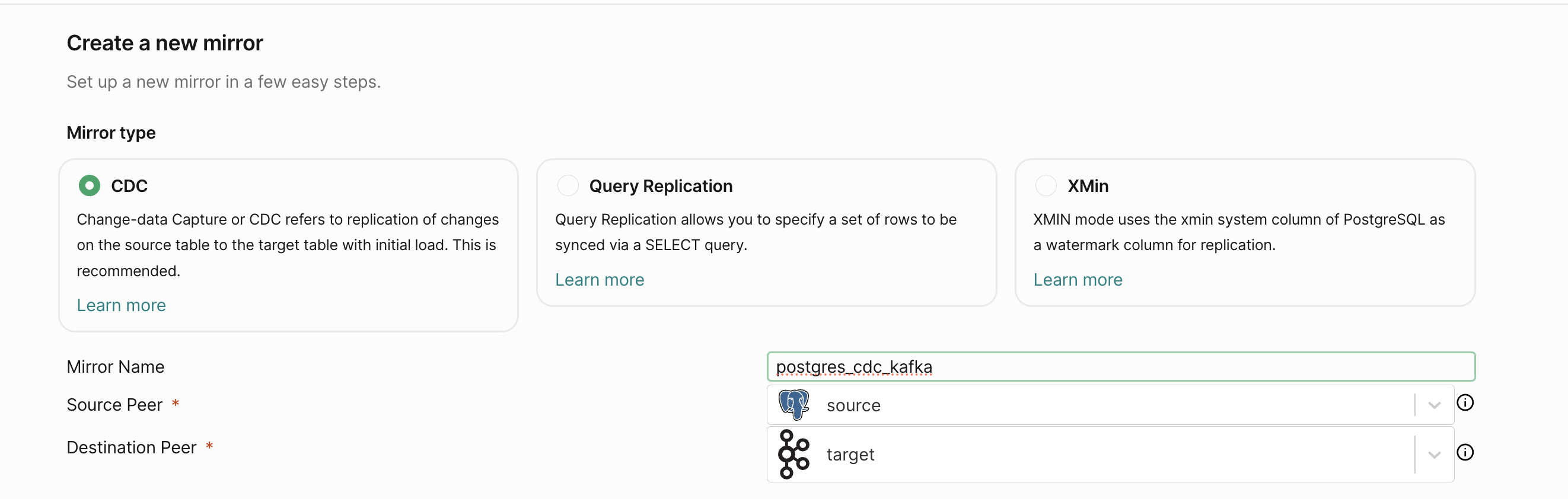
Mirror Type
Since in this walk through we are focussing on CDC based replication, choose CDC as the mirror type.
3
Mirror Name
Enter a unique identifier for the mirror name. This is used to identify the mirror in the PeerDB UI. Make this alpha numeric and without any special characters except underscore. Typically users use something like: prod_pg_to_kafka_v1 or dev_pg_to_kafka.
4
Select Source and Destination Peers
Select the source and destination peers that you created in the prerequisites in the drop down.
source and destination drop down
5
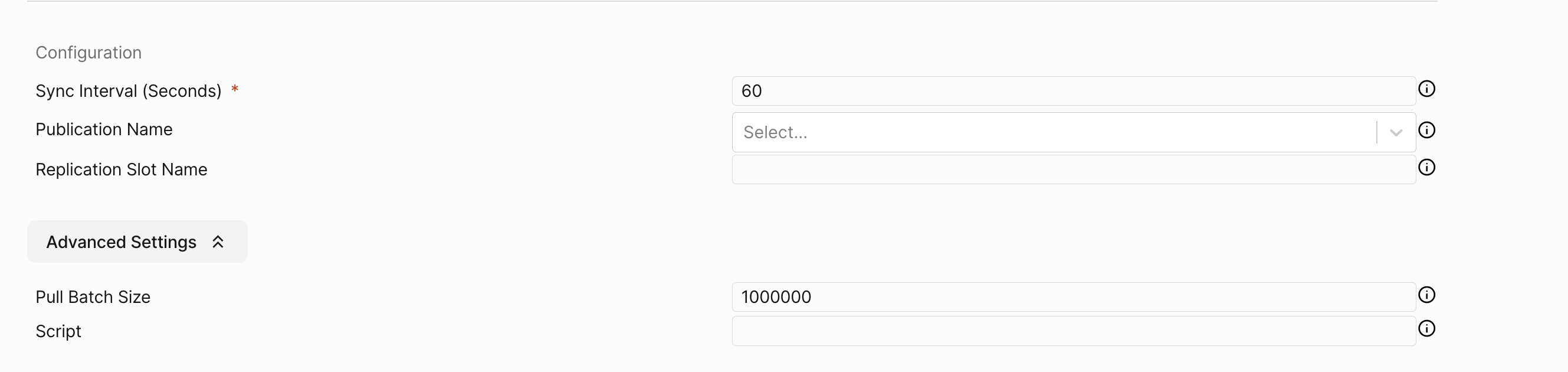
Mirror Configuration
Sync Interval (Seconds): This is the interval after which PeerDB will re-establish a connection to the source database. In case of queues the recommended value is over 600 seconds.
Publication Name: This is the name of the publication that you created in the source database. This is used to capture changes from the source database. If you have not created a publication, you can leave this blank and PeerDB will create a publication for you. If you have already created a publication dedicated to peerdb (peerdb_publication), don’t forget adding that in this field.
Replication Slot Name: This is the name of the replication slot that you created in the source database. This is used to capture changes from the source database. If you have not created a replication slot, you can leave this blank and PeerDB will create a replication slot for you.
Script: This is the script that you want to use to transform the data from the source database to the destination database. You can use the default script which writes to JSON or you can create your own script, see: Scripting.
Replication Slot Name
6
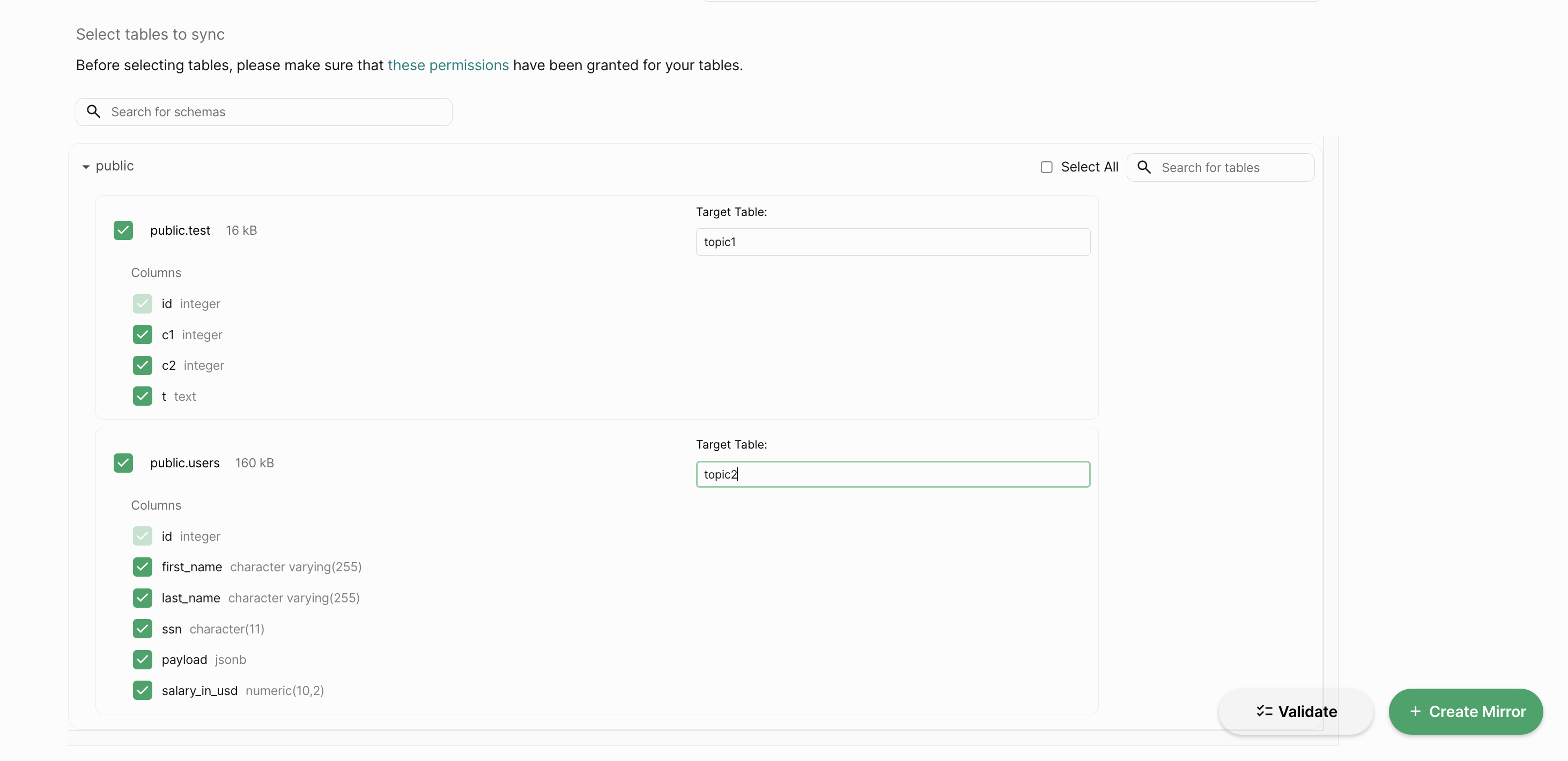
Table Selection
Select the tables that you want to replicate from the source database to the destination Kafka Server. You can use the search bar to search for the tables. You can also use the filter to filter the tables based on the schema. You can specify the destination topic name, by default we create a topic with the name <source_schema>.<source_table>.
If broker does not have automatic topic creation enabled you will have to create the topic ahead of time and give it to PeerDB. Automatic topic creation in Kafka Connect is controlled by the topic.creation.enable property. The default value for the property is true, enabling automatic topic creation, as shown in the following example:
topic.creation.enable = true
To prevent slot growth on the source database, it will be useful to create the heartbeat table. See this guide for detailed information: guide.
Table Selection
7
Review and Create
Review the mirror configuration and click on the Validate Mirror button. If there are any errors, you will see them on the screen. If there are no errors, you will see a success message. Once you see the success message, click on the Create Mirror button to create the mirror ✨.
When dealing with tables that feature TOAST columns, it’s essential to configure the replica identity to FULL to enable PeerDB to accurately capture changes to these columns.
Setting REPLICA IDENTITY FULL on tables that include primary keys—or when operating on PostgreSQL 16 — typically imposes minimal overhead on the primary server.
For an in-depth analysis, refer to this detailed blog post on the performance implications.