Demo
This demo shows PeerDB syncing a table with 100 million rows from PostgreSQL to PostgreSQL in few minutes using parallelized initial load and change data capture.Scenario
Suppose you have a banking application running on PostgreSQL. There are two tables: “users” and “transactions.” You want to sync these tables in real-time to another PostgreSQL server. Let’s see how we can make this happen within a few minutes and a few SQL commands using PeerDB.Prerequisites
- Enable logical decoding in Postgres. Ensure that the following settings/GUCs are properly configured:
- wal_level: logical
- max_wal_senders: >1
- max_replication_slots: 4
- Enable replication access for a PostgreSQL user - ALTER USER pg_user REPLICATION;
- Ensure that both tables have primary keys. Composite primaries are also fine. If not, make sure your tables have REPLICA IDENTITY FULL.
- If you are using PostgreSQL on the cloud, below links capture how to enable logical replication for each cloud:
Step 1: Create Two PostgreSQL Peers
Run the following commands to let PeerDB know about the existingpeers.(…) with the appropriate connection details for the two PostgreSQL instances. More details on adding PEERs are available here.
Step 2: Real-Time CDC from PostgreSQL to PostgreSQL
With the peers set up, you can create a mirror that facilitates real-time CDC from PostgreSQL to PostgreSQL.WITH clause captures if you wanted to include initial snapshot as a part of the MIRROR. If you don’t include that WITH, peerdb assumes that you don’t want to perform an initial snapshot. If just reads the slot and replays the changes to the target.
Step 3: Validate the Mirror
Through the same PeerDB’s Postgres-compatible SQL interface, you can quickly validate the MIRROR (real-time CDC).Step 4: Monitor the MIRROR
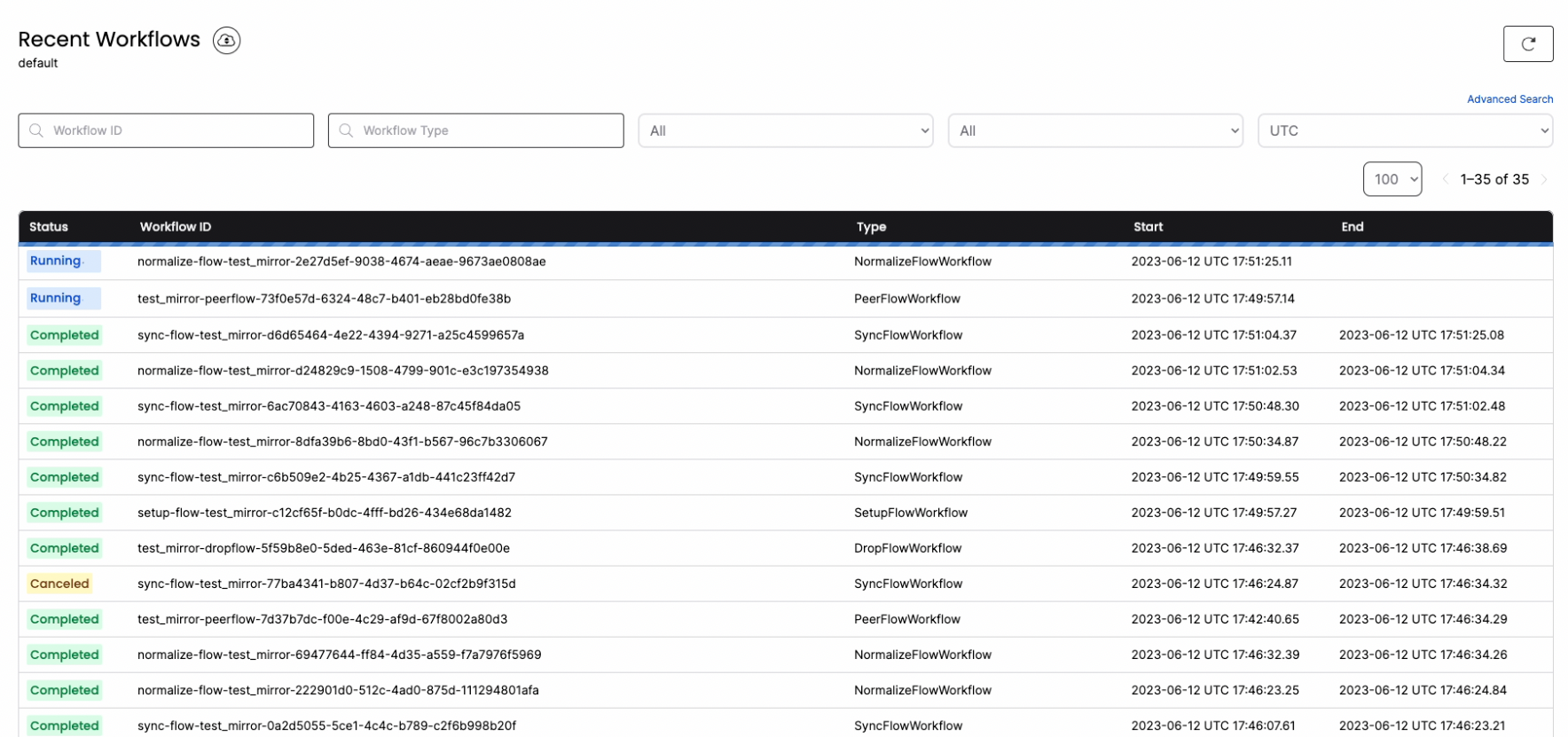
You can connect tolocalhost:8085 to get full visibility into the different jobs and steps that PeerDB is taking under the covers to manage the MIRROR.