BigQuery as a destination is deprecated and no longer actively maintained. It remains fully functional and no code is currently being removed. For new mirrors, we recommend ClickHouse, ClickHouse Cloud, or Postgres as the destination. Note that BigQuery remains a supported source.
Scenario
Suppose you have a banking application running on PostgreSQL. There are two tables: “users” and “transactions.” You want to sync these tables in real-time to BigQuery for analytics purposes, such as real-time fraud detection. Let’s see how we can make this happen within a few minutes and a few SQL commands using PeerDB.
Prerequisites
- Enable logical decoding in Postgres. Ensure that the following settings/GUCs are properly configured:
- wal_level: logical
- max_wal_senders: >1
- max_replication_slots: 4
- Enable replication access for a PostgreSQL user - ALTER USER pg_user REPLICATION;
- Ensure that both tables have primary keys. Composite primaries are also fine. If not, make sure your tables have REPLICA IDENTITY FULL.
- If you are using PostgreSQL on the cloud, below links capture how to enable logical replication for each cloud:
- AWS RDS and Aurora PostgreSQL
- Azure Database for PostgreSQL - Flexible Server
- GCP Cloud SQL PostgreSQL
Step 1: Add Postgres and BigQuery Peers
Run the following commands to let PeerDB know about the existing Postgres and BigQuery Peers.
-- Connect to PeerDB
psql "port=9900 host=localhost password=peerdb"
-- Add Postgres and BigQuery peers
CREATE PEER postgres_peer FROM postgres (...);
CREATE PEER bigquery_peer FROM bigquery (...);
(…) with the appropriate connection details for both the PostgreSQL and BigQuery instances. More details on adding PEERs are available here.
Step 2: Real-Time CDC from PostgreSQL to BigQuery
With the peers set up, you can create a mirror that facilitates real-time CDC from PostgreSQL to BigQuery.
Create MIRROR using SQL
-- Real-time CDC from PostgreSQL to BigQuery
CREATE MIRROR real_time_cdc
FROM postgres_peer TO bigquery_peer
WITH TABLE MAPPING (public.transactions:transactions, public.users:users)
WITH (
do_initial_copy = true,
snapshot_sync_mode='avro',
snapshot_num_rows_per_partition = 500000,
snapshot_max_parallel_workers = 4,
snapshot_num_tables_in_parallel = 4,
snapshot_staging_path = '<your_gcs_bucket>' // Needed for AVRO snapshot mode
);
sql mode.
To perform CDC via AVRO mode, you must set the following:
cdc_sync_mode = 'avro'
cdc_staging_path = '<your_gcs_bucket>'
WITH clause captures if you wanted to include initial snapshot as a part of the MIRROR. If you don’t include that WITH, peerdb assumes that you don’t want to perform an initial snapshot. If just reads the slot and replays the changes to the target.
- Data type mapping between Postgres and BigQuery.
- If you want additional types to be supported or want to alter the existing data type mapping, please reach out to us. We can aim to support that within a few days. Also, PeerDB is fully open source, so feel free to submit a PR.
PeerDB also supports replicating TOAST columns very efficiently. Unlike most CDC tools, you don’t need to set up REPLICA IDENTITY FULL for replicating TOAST columns. This PR captures the infrastructural optimizations that PeerDB takes to support TOAST columns.
Create MIRROR using UI
If you prefer a UI, you can easily create a mirror using the PeerDB UI (localhost:3000). Refer to the below video:
Step 3: Validate the Mirror
Through the same PeerDB’s Postgres-compatible SQL interface, you can quickly validate the MIRROR (real-time CDC).
-- Validate the mirror
SELECT COUNT(*) FROM bigquery_peer.transactions;
SELECT COUNT(*) FROM postgres_peer.public.transactions;
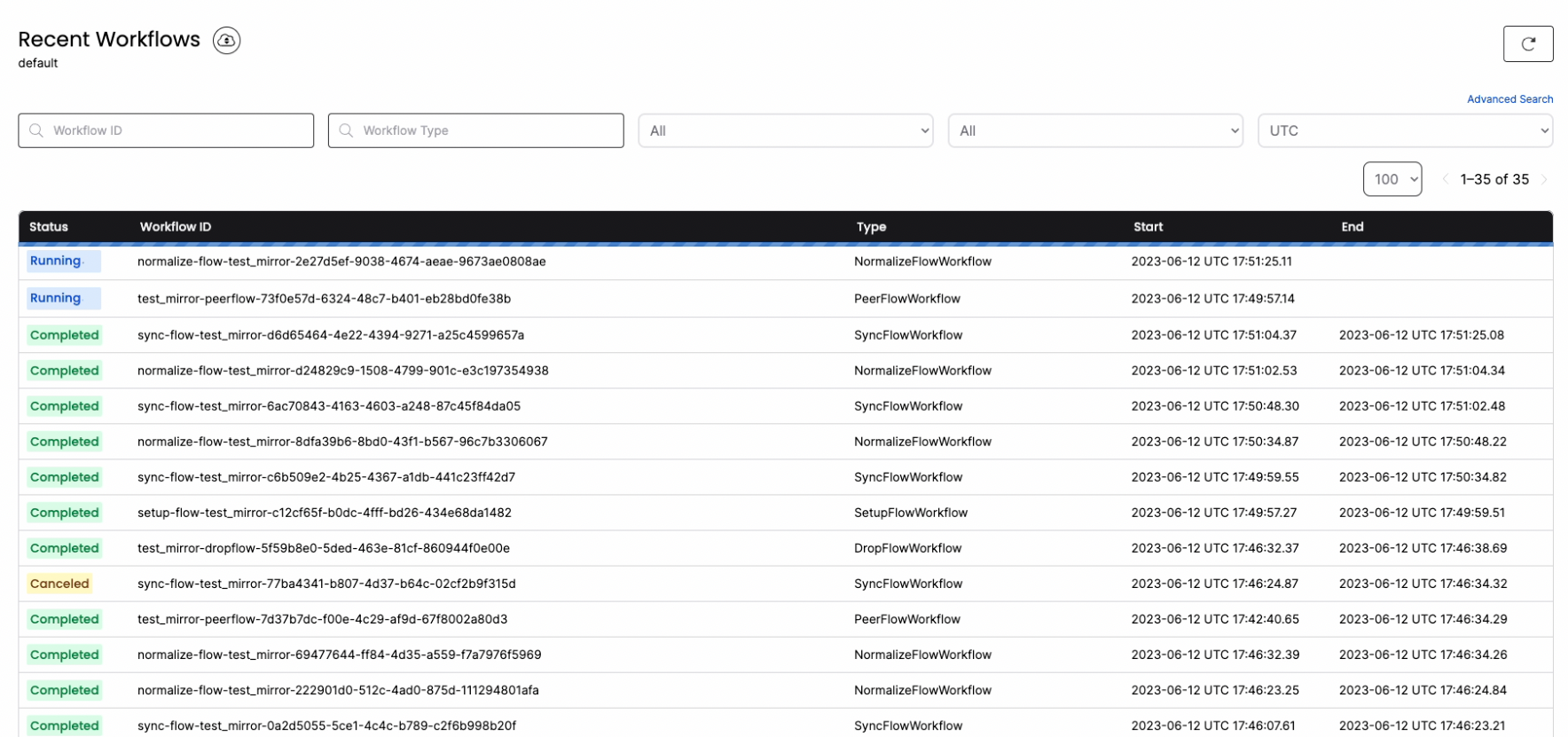
Step 4: Monitor the MIRROR
You can connect to localhost:8085 to get full visibility into the different jobs and steps that PeerDB is taking under the covers to manage the MIRROR.
Coming Soon
- Support for tables without primary keys using UNIQUE index or REPLICA IDENTITY FULL will be added in a few weeks.
- Handling Schema Changes will be added in a few weeks.
Support
If you run into any issues, join our slack channel and reach out to us. You can file an issue on our gihub repository or reach out to founders@peerdb.io . We will follow up!