Azure Event Hubs as a destination is deprecated and no longer actively maintained. It remains fully functional and no code is currently being removed. For new mirrors, we recommend ClickHouse, ClickHouse Cloud, or Postgres as the destination.
Scenario
Suppose you have a banking application running on PostgreSQL. There are two tables: “users” and “transactions.” You want to sync these tables in real-time to Event Hubs topics. Let’s see how we can make this happen within a few minutes and a few SQL commands using PeerDB.
Prerequisites
- Enable logical decoding in PostgreSQL. Ensure that the following settings/GUCs are properly configured:
- wal_level: logical
- max_wal_senders: >1
- max_replication_slots: 4
- Enable replication access for a PostgreSQL user - ALTER USER pg_user REPLICATION;
- Ensure that both tables have primary keys. Composite primaries are also fine. If not, make sure your tables have REPLICA IDENTITY FULL.
- If you are using PostgreSQL on the cloud, below links capture how to enable logical replication for each cloud:
- AWS RDS and Aurora PostgreSQL
- Azure Database for PostgreSQL - Flexible Server
- GCP Cloud SQL PostgreSQL
Step 1: Add PostgreSQL and Event Hubs Peers
Run the following commands to let PeerDB know about the existing PostgreSQL and Event Hubs Peers.
Make sure to replace (…) with the appropriate connection details for both the PostgreSQL and Event Hubs instances. More details on adding Peers are available here.
Step 2: Real-Time CDC from PostgreSQL to Event Hubs
The mirror from PostgreSQL to Eventhubs is unique, in the sense that you can sync source tables across namespaces,
and you can specify a column whose values will be used to route data into the partitions of the event hub.
To facilitate real-time Change Data Capture (CDC) from PostgreSQL to Event Hubs, set up your peers and then create a mirror using the following SQL syntax:
Example:
Parameters:
mirror-name: Desired name for the mirror.postgres-peer-name: Name of the PostgreSQL peer.eventhubs-peer-name: Name of the Event Hubs group peer.namespace-name: Name of the namespace in which you wish to sync to an eventhub.eventhub-name: Name of the eventhub in which you wish to sync the data. PeerDB creates the eventhub for you if it doesn’t exist already.partition_key_column: Column in the source table whose values will be used to route data into the partitions of the event hub.max_batch_size: Maximum number of records in a batch.publication_name: Name of the publication.
Remember to adjust placeholder values (<…>) with your specific details and preferences.
The example above has been abbreviated for clarity; ensure you provide all the necessary mappings and configurations in practice.
Step 3: Validate the Mirror
Validate the mirror by checking if the number of messages in the topics matches the row count on the source table.
Step 4: Monitor the MIRROR
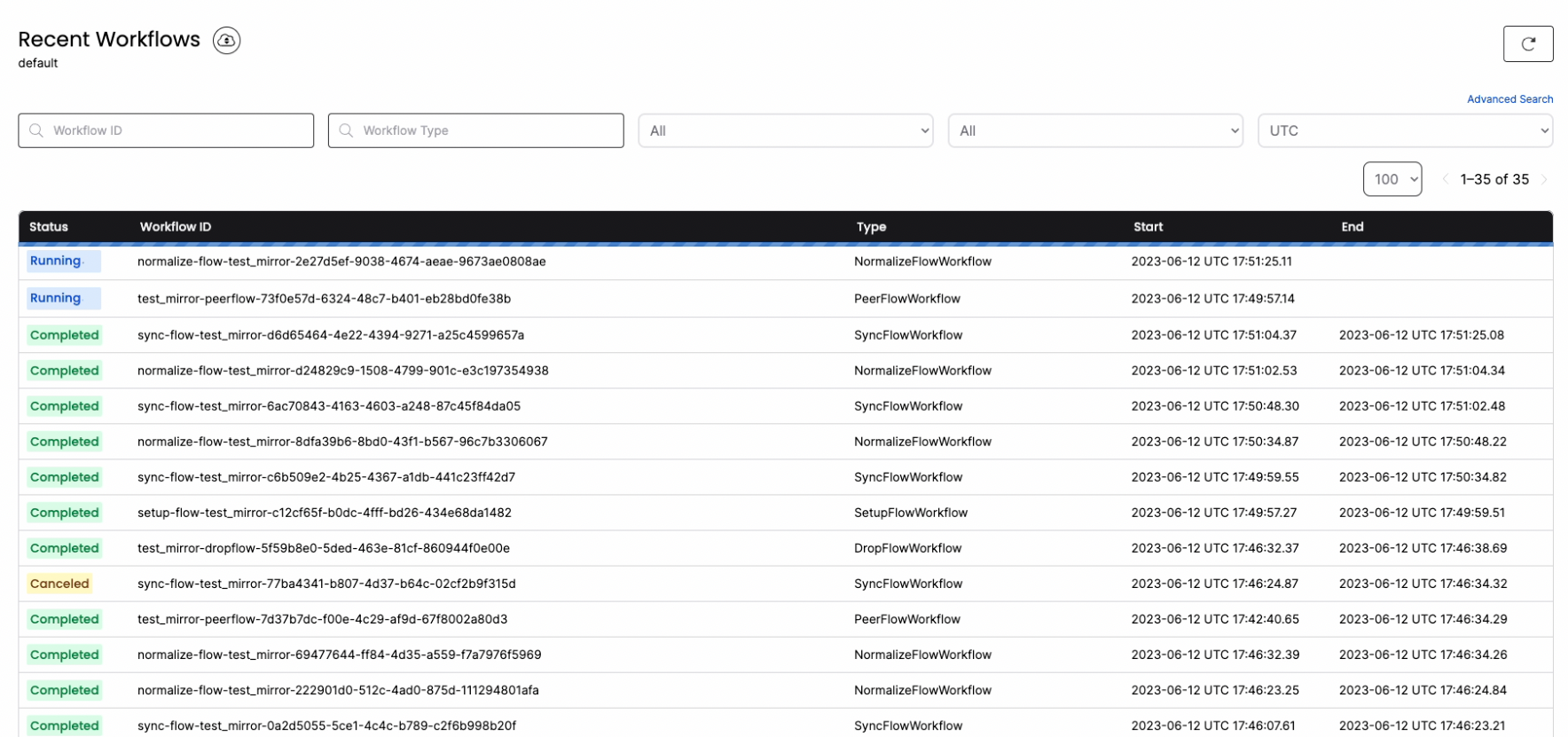
You can connect to localhost:8085 to get full visibility into the different jobs and steps that PeerDB is taking under the covers to manage the MIRROR.
Step 5: DROP MIRROR
To make it easy in your development and test environments, PeerDB also introduces the DROP MIRROR command. DROP MIRROR drops all the underlying objects that CREATE MIRROR generates. More details are available in this PR.