Assumptions
Airbyte’s benchmark was performing a one-time transfer of a single large table from Postgres to Snowflake. Since we are moving data already present in the source table instead of incrementally moving fresh data, this is what we call a Full Refresh in Airbyte and an Initial Snapshot in PeerDB. Benchmarking a large migration like this is highly dependent not only on the performance of the migration platform but also on the performance of the source Postgres and target Snowflake instances. Network throughput between all these parts is also crucial. So we generated a dataset and tested PeerDB and Airbyte against it, using instances for Postgres and Snowflake which we felt best represented a production deployment. The entire infrastructure was positioned within a single AWS region, reducing network bottlenecks. More details on the setup can be found here.Generating the Data
While Airbyte provided the schema of the table, it wasn’t enough to generate a dataset, as we didn’t know the size of a row or the number of rows in the table. We decided to run the test on a table with 6 billion rows and a 1.5TB size. We worked out that each row should be around 230-235 bytes. We then arrived at a size for each variable length field that should get us the table size we wanted. We also converted one of the columns in the table to be a generated primary key because PeerDB currently requires one for CDC mirroring.Testing!
Both AirByte and PeerDB have an Open Source offering and are available as Docker Compose Applications. So we decided to use these for our testing, on a sufficiently powerful AWS EC2 instance. To reiterate, we are only looking for the performance of the initial load, and not an incremental sync.Airbyte
With Airbyte, we already knew from their numbers that a run could take multiple days. So after deploying Airbyte and setting up our connectors, we kicked off a run, checking in once every few hours. After an initial failure because of hitting a timeout (of 72 hours), Airbyte completed successfully. It took 83 hours to move the table to Snowflake.
PeerDB
PeerDB implements parallelism for these heavy initial loads, and we launched five runs in total with 1, 8, 16, 32 and 48 parallel threads. With 32 and 48 threads, PeerDB moved over 1.5TB of Postgres table in under 5 hours. Even scaling down to 8 threads, we still see a runtime of under 9 hours. This performance derives from the optimizations PeerDB has done to make reads as efficient as possible and also the parallelism multiplier. Airbyte does not support parallelism at the moment. We decided to do an additional run with parallelism set to 1, as a fair comparison to Airbyte. With this, we got a run time of 43 hours.Results
Airbyte took 83 hours to move a 1.5TB table from Postgres to Snowflake. With a parallelism of 32 threads, PeerDB took 5 hours to do the same job. So PeerDB was 16x faster. Even considering a single-threaded run, PeerDB is ~2x faster. We felt that a comparison with Fivetran was out of scope for this article. Airbyte had already shown that Fivetran was slower than Airbyte and we could expect a full refresh to take 150+ hours.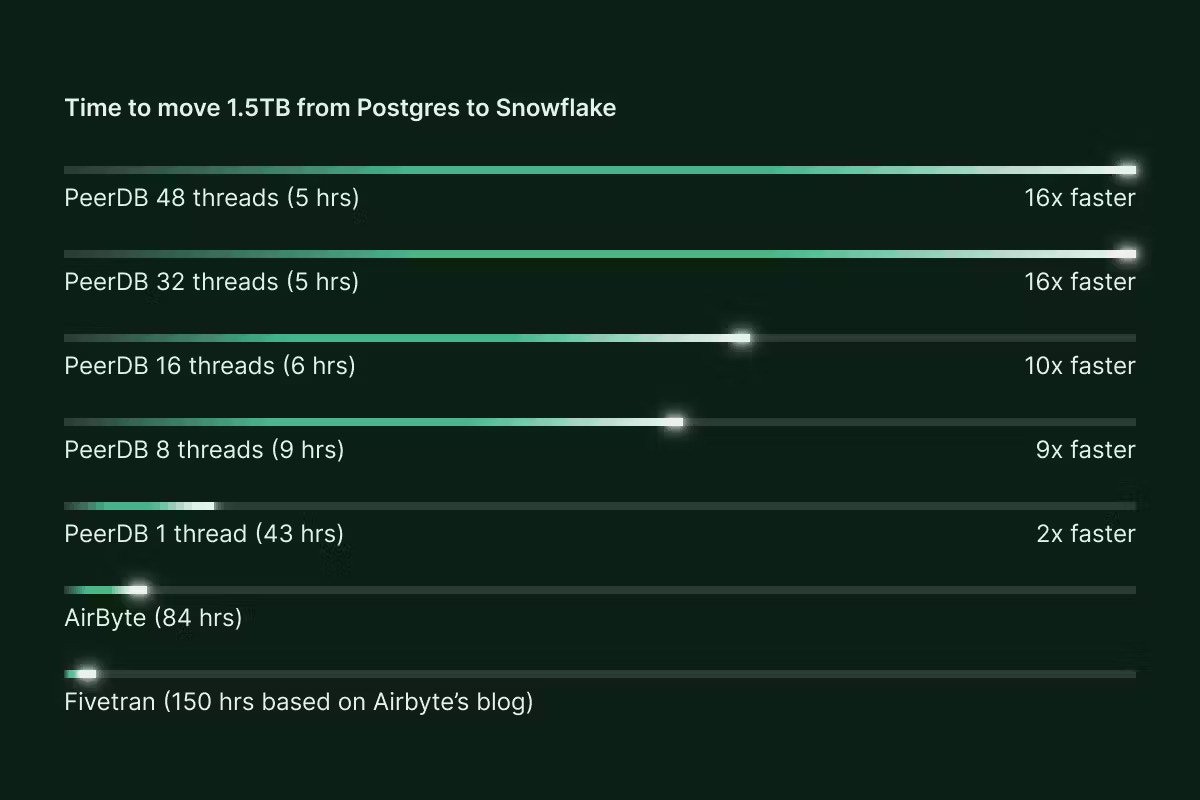
What makes PeerDB faster?
Parallelism
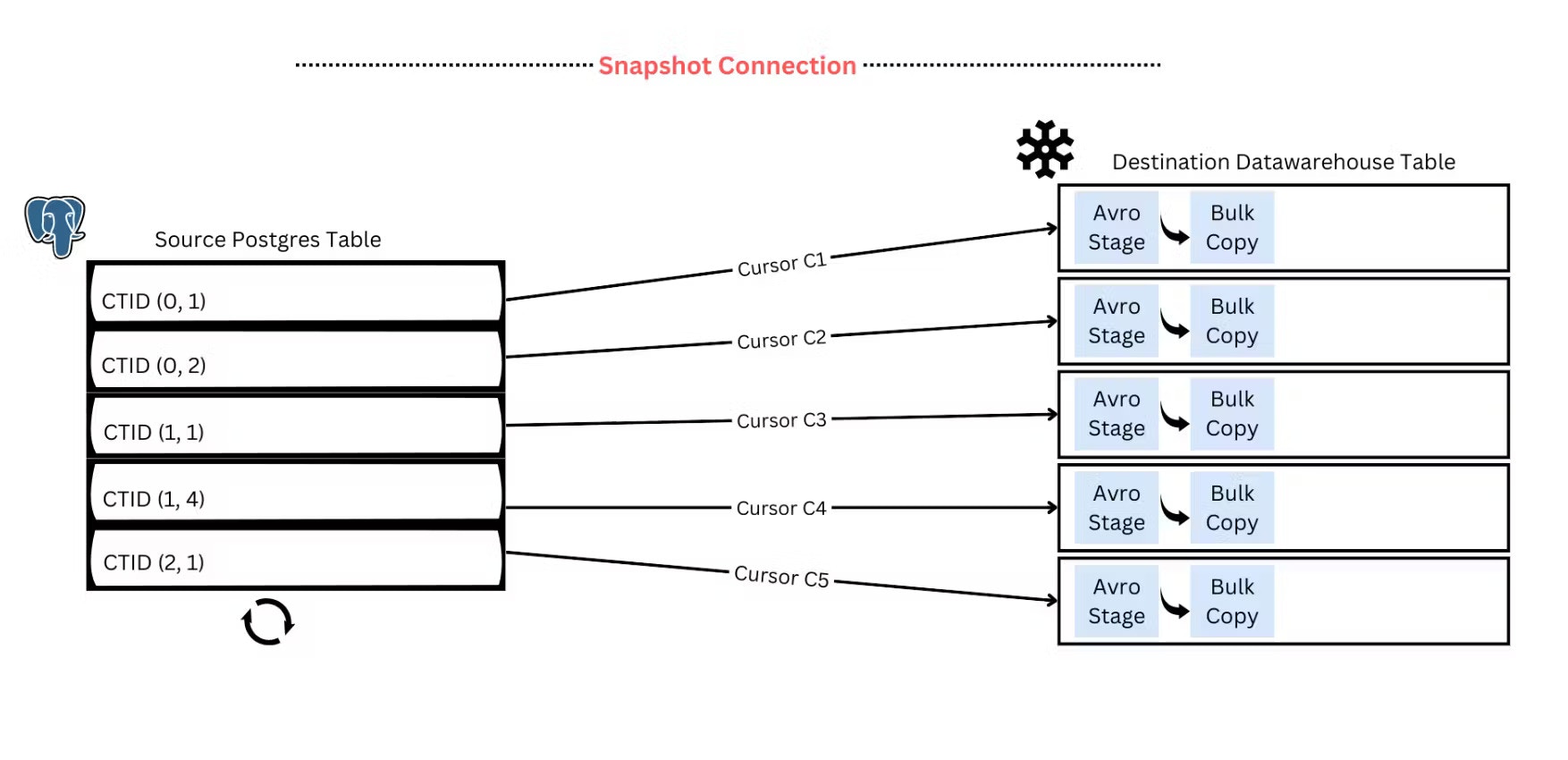
One of the more obvious reasons is our early adoption of parallelism for long-running operations such as moving large tables from Postgres to Snowflake. We do this by logically partitioning the large table based on internal tuple identifiers (CTID) and parallelly streaming those partitions to Snowflake. The implementation is inspired by this DuckDb blog. Based on the load you can put on the source Postgres database, you can configure the parallelism for the sync. More details can be found in this blog